スタメン エンジニアの津田です。スタメンで運営しているサービス、「TUNAG」では、毎日、データベースの"その日の状態"を別々のデータベースとして残していました。こちらの運用を、AWSのS3、Glue、Athenaを利用して置き換えたのですが、その中で利用した、MySQL互換Auroraから、S3上へのデータ抽出用スクリプトの紹介をいたします。
TL;DR (概要)
TUNAGでは、データベースとして、Amazon Aurora(MySQL互換)を使用しています。サービス利用状況の分析などで、過去の特定時点でのデータベースが必要となるため、いままでは、日次でデータベースのコピーを作成し、一つのRDSインスタンス内に追加していました。
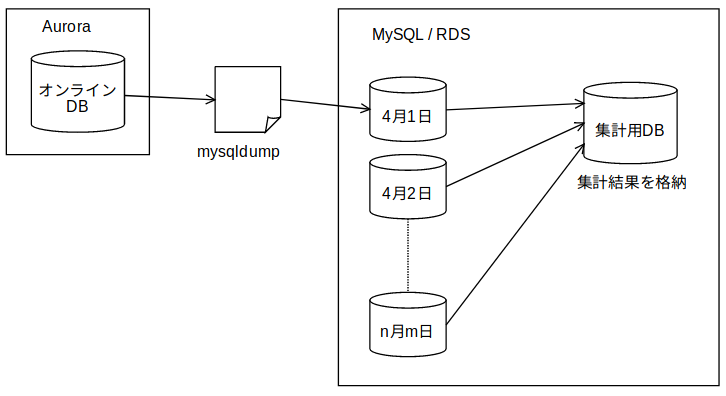
この形式では、全てを使い慣れたデータベース上で完結できるため、機能の構築は素早く行えたのですが、データ総量が日々増え、処理時間が次第に増大していました。なんらかの原因で処理が失敗した場合の再試行にかかる時間も含めると許容できない長さになりつつあったため、以下のように置き換えています。

Auroraのクローン機能を利用して特定時点でのDBクローンを作成した上で、AWS Glueジョブで各テーブルの内容をparquet形式でS3上に抽出し、データの利用はAthena経由としています。
今回紹介するのは、図の黄色い部分で使用したGlueジョブのスクリプトです。
Glueを利用してS3にファイルを作成する
AWS Glueは抽出、変換、ロード (ETL)を行うマネージド型のサービスです。今回は、Auroraのテーブルをそのままの形でファイルとして出力するだけなので、AWS Consoleの「Add job」ボタンから、コードを一行も書かずに処理を作成することも可能です。
ただ、その場合、
- まず、出力元のデータベースに対しクローラーを設定しデータカタログを作成
- テーブル数だけGlueのジョブを作成
- 今後、テーブルの追加があった場合、手動で個別にジョブを追加
といった手順が必要となります。元になるデータベースへのテーブル追加はそれなりの頻度で発生するため、そのたびにジョブを作成するのは嬉しくありません。そこで、生成されたスクリプトをベースに、mysqlのinformation_schemaを参照して、データベース内の全てのテーブルを調べて抽出するよう変更しました。
import sys import datetime from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job # ジョブのパラメーターを取得 arg_keys = ['JOB_NAME', 'jdbc_url', 'db_user', 'db_password', 'bucket_root', 'db_schema'] args = getResolvedOptions(sys.argv, arg_keys) (job_name, jdbc_url, db_user, db_password, bucket_root, db_schema) = [args[k] for k in arg_keys] # Athenaで利用する際、パーティション分割をするため、年月日を取得しておく now = datetime.datetime.now() date = [now.year, now.month, now.day] sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session # 全テーブルを対象とするため、まず、information_schemaのテーブル情報を取得 df = glueContext.create_dynamic_frame_from_options( 'mysql', connection_options={ "url": jdbc_url + "information_schema", "user": db_user, "password": db_password, "dbtable": "tables" } ) # 抽出する必要がないテーブルはfilterで弾いておく。ar_internal_metadataはRailsが自動生成するテーブル target_tables = df.toDF().filter("TABLE_SCHEMA = '{0}' AND TABLE_NAME <> 'ar_internal_metadata'".format(db_schema)).collect() # 1テーブルずつ抽出 for row in target_tables: table_name = row['TABLE_NAME'] ds = glueContext.create_dynamic_frame_from_options('mysql', connection_options={ "url": jdbc_url + "dbname", "user": db_user, "password": db_password, "dbtable": table_name }) # S3上にdynamic frameを書き出す。パスには、パーティションを付加しておく glueContext.write_dynamic_frame.from_options( frame=ds, connection_type="s3", connection_options={"path": bucket_root + table_name + "/YEAR={0[0]:0>4}/MONTH={0[1]:0>2}/DAY={0[2]:0>2}".format(date)}, format="parquet" )
実行数を調整する
Glueのジョブには、Maximum capacityという項目があり、スケールアウトするために使用できるデータ処理単位(DPU)を指定できます。これはデフォルトでは10に設定されているのですが、DPU の容量計画のモニタリングを参考にメトリクスを確認したところ、先述のスクリプトの書き方ではDPUを使い切れていなかったので、適当と思われる数字に減らして設定し直しました。
1 つの DPU はアプリケーションマスター用に予約されています。9 個の DPU はそれぞれ 2 つのエグゼキュターを実行し、1 つのエグゼキュターは Spark ドライバー用に予約されています。そのため、割り当てられるエグゼキュターの最大数は、2*9 - 1 = 17 です。
DPU の容量計画のモニタリングに以上のように書かれているので、エグゼキュターの数は、DPU x 2 - 3になると思われます。つまり、DPU2だと利用できるエグゼキュータ数は1ですが、DPU3だと3で、三倍になります。もし、エグゼキューター時間3で終わる処理があるとすると、DPU2では3/1で3時間、DPU3なら3/3で1時間で終わります。Glueの課金はDPU時間あたりなので、DPU3(3 x 1時間 = 3)であれば、DPU2(2 x 3時間 = 6)の半額で済む計算です。Maximum capacityは、必要とされるエグゼキュターの数を上回らない範囲で大きな値を設定すると、処理が早く、かつ、費用が抑えられることになると思われます。
まとめ
Glueを利用してデータを抽出する部分を紹介させていただきましたが、生成されたファイル利用してをAthena経由で集計、結果を分析用データベースにロードするなど、後続の処理はAWS LambdaでRubyスクリプトを使って実装しています。こちらについては、@uuushiroが名古屋Ruby会議04で発表しますので、よろしければお越しください。
また、AWS Summit Tokyo内で行われる、Startup Architecture of the Year 2019にも出場させていただきますので、よろしくお願いします。