
目次
はじめに
こんにちは、スタメンの田中、若園です。
こちらの記事でカスタムダッシュボード機能の全体像を紹介しました。🎉
この記事では、続編その1として、カスタムダッシュボード機能におけるLambda関数を活用したQuickSightのSPICEデータ更新の方法と実装について紹介していきます。
データ更新のニーズと課題について
分析の元となるデータは、処理速度やコストのメリットを考慮しSPICEにデータを格納しています。
データ更新においては下記のニーズがありました。
- ① 日次の定期更新
- 毎日TUNAG上に利用データが蓄積されるため、最新の利用データがSPICEデータに毎日反映されるようにし、分析できるようにしたい。
- ③「更新ボタン」からの即時更新
- ユーザー情報、部署の所属情報、セグメント機能で設定したセグメントの対象の変更などが発生した場合に即時に分析に反映したい。
- 即時の更新をTUNAGの管理画面からユーザー操作で行えるようにしたい。
これらのニーズがある中で、QuickSightコンソールで提供されている機能を利用してデータ更新が行えないか検討しましたが、下記のような課題がありました。
- ① 日時の定期更新
- スケジュール更新機能は、QuickSightコンソールから都度設定を行う必要があり、工数がかかる。
- データセット同士の結合が頻繁に発生するため、スケジュール設定の漏れが懸念される。
- ②「更新ボタン」からの即時更新
- 即時で変更を反映するためには、QuickSightコンソールで手動更新を行う必要があり、工数がかかる。
今後導入の拡大を狙う上で、QuickSightコンソール上での作業による工数がボトルネックになることが懸念されました。 そのためQuickSightから提供されているAPIを使用し、独自で自動更新の仕組みを実装することとしました。
API経由でのSPICEデータの更新方法
API経由でのSPICEデータの更新方法は下記の2通りあります。
- ① CreateIngestion API
- SPICEデータの更新処理を開始する。
- 24時間あたり32回までのサービスクォータが設定されている。
- ② UpdateDataSet API
- データセット更新処理後に、SPICEデータの更新が実行される。
サービスクォータを考慮して、UpdateDataSet APIを使用して自動更新を実行するLambda関数を実装しました。
(サービスクォータを引き上げて欲しい。。。)
自動更新のアーキテクチャ
自動更新の実現に向けた課題
自動更新の実現に向けて下記の課題がありました。
- ① 親子関係を持つデータセット群の更新において、親データセットを更新した後に子データセットを更新するようにしたい。
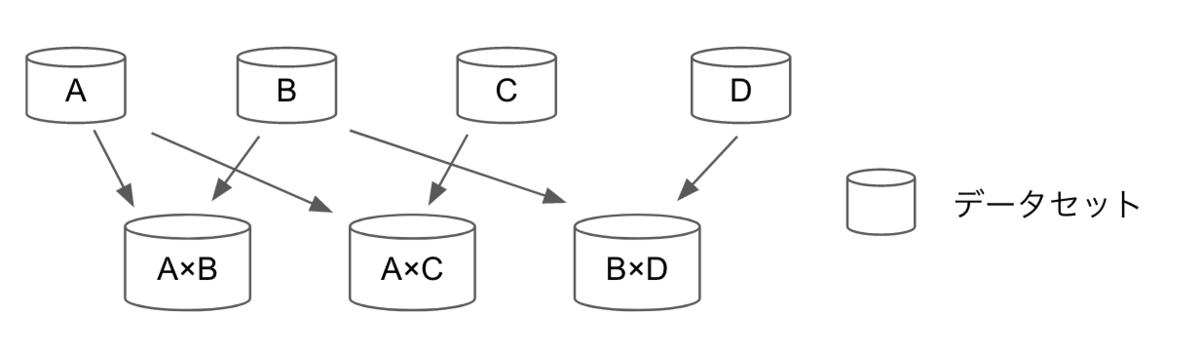
- カスタムダッシュボード機能では、例えばユーザー情報などのマスターデータと投稿などのトランザクションデータを結合して、ユーザー別の投稿数などといったデータセットを作成しています。
- 結合済みのデータセットとマスター/トランザクションデータとの間に下図のような親子関係が発生します。データの中身を最新にするに当たり、親データセットを更新した後に、子データセットを更新する必要がありました。
- ② SPICEデータ更新時にAuroraもしくはAthenaへの多重リクエストを最小限にしたい。
- 更新時にAuroraもしくはAthenaに対してデータをクエリするため、全てのデータセット更新を実行した場合の負荷や同時接続数が懸念されました。
Lambda関数を活用したアーキテクチャの概要
前述の課題解決にあたり、下図のように2つのLambda関数を組み合わせた構成で自動更新フローを構築しました。

2種類の更新方法について、それぞれ流れを紹介します。
日時の定期更新
日時の定期更新はEventBridgeでルールを設定し、毎朝早朝に更新が実行されるようにしています。 EventBridgeから、ECSタスクを起動し、一部データをQuickSightで扱う形式に変換する処理の実行を行います。 その後、QuickSight上のデータセット同士の依存関係の解決を行う関数(以下、関数その1)が起動されます。
関数その1では、データセット同士の依存関係を解決し、データセットIDを更新順に配列化します。 その後、データセット更新用のLambda関数(以下、関数その2)を起動し、更新順の情報を渡します。
関数その2は、1番目に更新するデータセットの更新をUpdateDataSet APIで実行し、更新が完了するまで待ちます。 更新が完了したら、更新順の配列情報と次の更新対象を示すインデックス情報を渡し、次のデータセット用の関数その2を起動します。
そして、最後のデータセットの更新が終わると、SNS経由でTUNAGに更新完了を通知します。
「更新ボタン」からの即時更新
即時更新は、TUNAG上の更新ボタンを押下することで実行されます。その後の流れは定期更新と同じとなります。 即時更新の場合では、更新対象がマスターデータと結合済みのデータセットの2種類のみとなるように絞り込みをしており、データ量が多いトランザクションデータは、日時で定期更新される前日分までの利用データを分析で使用するようにしています。
このように関数その1, その2を組み合わせて、データセット同士の依存関係の解決と更新順に順次実行することで、前述の課題を解消しました。
Lambda関数のコード
最後にLambda関数のコードを記載しておきます。
関数その1
require 'json' require 'aws-sdk' def handler(event: nil, context: nil) @quicksight_client = Aws::QuickSight::Client.new(region: ENV['REGION']) # 企業IDを元にデータセットをフィルタリングする company_id = event['company_id'] # 日時の定期更新なのか、「更新ボタン」からの即時更新なのかを判定するため # daily: 日時の定期更新 # manually: 「更新ボタン」からの即時更新 update_type = event['update_type'] # ListDataSets APIから企業毎にデータセットを絞り込む list_data_sets = list_data_sets_for(company_id) # 依存関係をDescribeDataSet APIから取得して、Hashを生成 unresolved_hash = generate_unresolved_hash(list_data_sets) # 依存関係を解決する resolved_data_set_ids = resolve_recursively(unresolved_hash) # トランザクションデータはdata_set_idの末尾に、transactionを付与している # 即時更新の場合はマスターデータと結合済みのデータセットに絞り込む if update_type == 'manually' resolved_data_set_ids = resolved_data_set_ids.reject { |data_set_id| data_set_id.end_with?('transaction') } end # 更新処理を行う関数その2を呼び、配列の0番地から開始する invoke_lambda_function(resolved_data_set_ids, company_id, update_type) end private def generate_unresolved_hash(list_data_sets) unresolved_hash = {} list_data_sets.each do |data_set| resp = @quicksight_client.describe_data_set( aws_account_id: ENV['AWS_ACCOUNT_ID'], data_set_id: data_set.data_set_id ) dependent_ids = resp.logical_table_map.map do |_, v| # 未結合のデータセットはdata_set_arnがnilが返る next if v.source.data_set_arn.nil? # 結合で生成されたデータセットは、arnを取得することが出来るため、id値のみ取得する v.source.data_set_arn.split('/').last end.compact! unresolved_hash[data_set.data_set_id] = dependent_ids end unresolved_hash end def resolve_recursively(unresolved_hash) resolved_array = [] unresolved_hash.each do |data_set_id, dependent_ids| resolve(data_set_id, dependent_ids, resolved_array, unresolved_hash) end resolved_array end def resolve(data_set_id, dependent_ids, resolved_array, unresolved_hash) return if resolved_array.include?(data_set_id) # 更新順序の依存関係を持たないデータセットの場合 return resolved_array.unshift(data_set_id) if dependent_ids.empty? # 更新順序の依存関係を持つデータセットの場合、依存先のデータセットを依存配列に含めるように再帰処理を行う dependent_ids.each do |dependent_id| if resolved_array.include?(dependent_id) && !resolved_array.include?(data_set_id) resolved_array.push(data_set_id) next else resolve(dependent_id, unresolved_hash[dependent_id], resolved_array, unresolved_hash) end end resolved_array.push(data_set_id) unless resolved_array.include?(data_set_id) end def invoke_lambda_for_start_to_update_datasets(data_set_ids, company_id, update_type) lambda_client = Aws::Lambda::Client.new(region: ENV['REGION']) lambda_client.invoke( function_name: '関数その2', invocation_type: 'Event', log_type: 'None', payload: JSON.generate( index: 0, # 最初は0番地を指定 data_set_ids: data_set_ids, company_id: company_id, update_type: update_type ) ) end
関数その2
require 'json' require 'aws-sdk' def handler(event: nil, context: nil) company_id = event['company_id'] # データセットの更新順の配列 data_set_ids = event['data_set_ids'] # 更新対象を示すインデックス情報 index = event['index'] # 日時の定期更新なのか、「更新ボタン」からの即時更新なのかを判定するため # daily: 日時の定期更新 # manually: 「更新ボタン」からの即時更新 update_type = event['update_type'] # 更新対象のデータセット data_set_id = data_set_ids[index] @quicksight_client = Aws::QuickSight::Client.new(region: ENV['REGION']) # データセットの存在確認 response_describe_data_set = @quicksight_client.describe_data_set( aws_account_id: ENV['AWS_ACCOUNT_ID'], data_set_id: data_set_id ).data_set # データセットの更新 resp_update_data_set = @quicksight_client.update_data_set( aws_account_id: ENV['AWS_ACCOUNT_ID'], data_set_id: data_set_id, name: response_describe_data_set.name, import_mode: 'SPICE', physical_table_map: response_describe_data_set.physical_table_map, logical_table_map: response_describe_data_set.logical_table_map ) # SPICEインポートの進捗確認 ingestion_status = wait_ingestion( resp_update_data_set.data_set_id, resp_update_data_set.ingestion_id ) if ingestion_status == 'COMPLETED' success_update( index, data_set_ids, company_id, update_type, { data_set_id: data_set_id, name: response_describe_data_set.name, company_id: company_id, lambda_function_name: context.function_name, lambda_request_id: context.aws_request_id, lambda_log_stream_name: context.log_stream_name } ) else # SNS経由でエラー通知 end end def wait_ingestion(data_set_id, ingestion_id) waiting = true while waiting resp_describe_ingestion = @quicksight_client.describe_ingestion( aws_account_id: ENV['AWS_ACCOUNT_ID'], data_set_id: data_set_id, ingestion_id: ingestion_id ) ingestion_status = resp_describe_ingestion.ingestion.ingestion_status case ingestion_status when 'FAILED', 'COMPLETED' waiting = false else sleep 3 end end ingestion_status end # 最後のデータセット更新の場合は、SNS経由で更新完了を通知 # それ以外は、次のデータセット更新を実行する def success_update(index, data_set_ids, company_id, update_type, message) if last_update?(data_set_ids, index) # SNS経由で更新完了を通知 else invoke_lambda_for_next_dataset(index, data_set_ids, company_id, update_type) end end def last_update?(data_set_ids, index) data_set_ids.length == index + 1 end def invoke_lambda_for_next_dataset(index, data_set_ids, company_id, update_type) lambda_client = Aws::Lambda::Client.new(region: ENV['REGION']) lambda_client.invoke( function_name: '関数その2', invocation_type: 'Event', log_type: 'None', payload: JSON.generate( index: index + 1, data_set_ids: data_set_ids, company_id: company_id, update_type: update_type ) ) end
まとめ
以上が、QuickSight SPICEデータのLambda関数を用いた自動更新処理の内容となります。 現在QuickSightの利用していて運用を効率化したいと考えている方にとって、少しでも参考になれば幸いです。
エンジニアとして、やりがいのある仕事がしたい!わくわくする仕事をしたい!という方がいらっしゃいましたらぜひ、弊社採用窓口までご連絡ください。
弊社開発部門では、開発体制や開発の流れ、採用している技術をエンジニアリングハンドブックにまとめております。ご興味がある方は下記のリンクからぜひご覧ください。