こんにちは。桑原です。 2度目の投稿となります。 今回は TUNAG のフィードに埋め込まれている Markdown の仕組みについて解説します。 ※ ソースコードは部分的な公開になるため、ご了承ください。
前置き
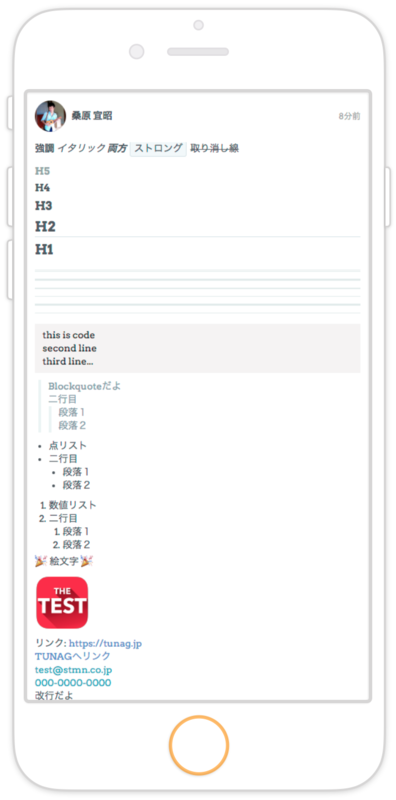
Markdown とは、テキストで HTML を表現するためのマークアップ言語です。 下記の画像のように、タイトルやプログラムコード、画像の埋め込みなど、多彩な表現が可能になります。
ところがこの Markdown、一般的な記法はあれど、標準化・規格化されていないことをご存知でしょうか? エンジニアの間では、 Markdown への対応はまさに 地獄 と評されてきました。 何故 地獄 と言われているのか、 Markdown の仕組みと散々苦しんだ私の愚痴話をしたいと思います。
網羅するべき多くの記法
ざっとあげると下記の通りです。
- 文字の強調、イタリック、もしくはその両方
- Strongタグ
- 取り消し線
- ヘッダー(h5〜h1)
- 区切り線(4種類)
- HR区切り線(2種類)
- Codeタグ
- Blockquoteタグ
- 点リスト
- 数値リスト
- チェックボックス(チェック入り、無し)
- 絵文字
- 画像
- リンク(URLそのまま、文字列にHrefのアタッチ)
- メール and 電話番号
- 改行
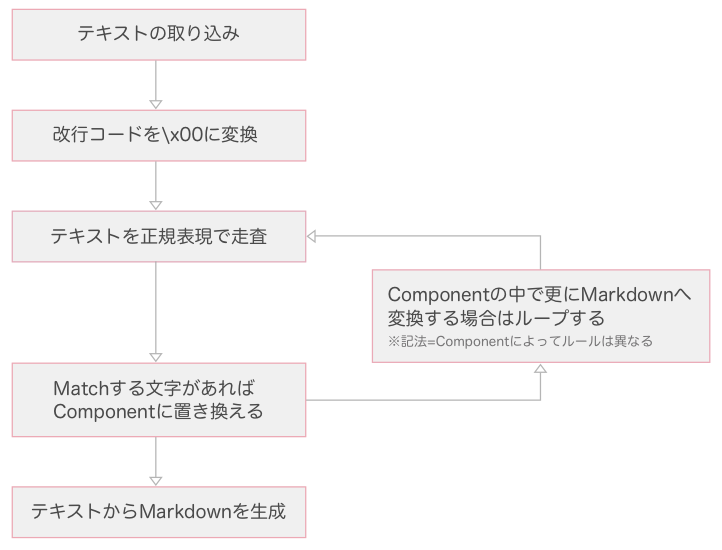
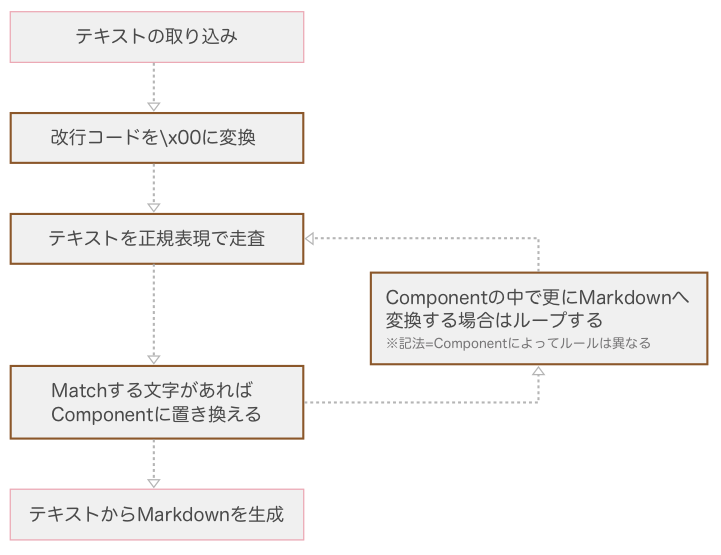
テキストに正規表現の走査・走査・走査...
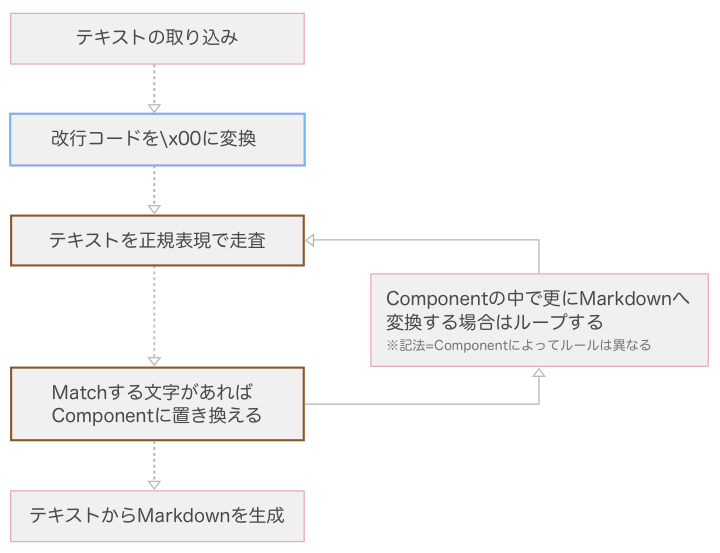
TUNAG ではフロントエンドの実装に React を採用しています。 Markdown でのアルゴリズムでは、テキストを正規表現で記法を検知し、 Markdown 用の React Component に置き換える、と言う方法で実装しています。 これを行う MarkdownParser の動きは下記の通りです。
Markdownの記法には大きく分けて下記の5パターン存在します。
- 太字のようなそれ単体で成立するもの
- Hタグのようにその記法の中でさらに別の記法が成立するもの
- Codeタグのように行をまたいで成立し、かつタグの中で別の記法が成立するもの
- 改行
- 1〜4のどれにも属さない文字列
これらのパターンに分けて、走査のアルゴリズムについて説明します。
1. Delタグのようなそれ単体で成立するもの
これは最も単純なパターンです。 該当する記法としては下記の通りです。
- 文字の装飾や取り消し線
- HR区切り線
- 絵文字
- 画像
該当する文字列が存在する場合、下記のコンポーネントが実行されます。 decoratedText には該当した文字列が引数として与えられるため、この文字列を del タグでくくって DOM を return するだけです。
const Del = ({ decoratedText }) => { const textRegExp = new RegExp(`(?:\\~){2,2}([^\\x00]+?)(?:\\~){2,2}`); const textMatch = decoratedText.match(textRegExp); if (!textMatch) { return null; } return ( <del className="markdown__del"> {textMatch[1] ? textMatch[1] : null} </del> ); };
2. Hタグのようにその記法の中でさらに別の記法が成立するもの
このパターンの場合は 1. の応用で実現します。 decoratedText が該当する文字列になるため、これを更に正規表現(二重が許される記法)で走査する、 replaceToComponentsメソッド を利用しています。 replaceToComponentsメソッド により、該当する正規表現があればコンポーネントに置き換わった戻り値が得られます。
const H1 = ({ decoratedText }) => { const textRegExp = new RegExp(`# ([^\\x00]*)`); const textMatch = decoratedText.match(textRegExp); if (!textMatch) { return null; } return ( <del className="markdown__h1"> {textMatch[1] ? replaceToComponents(textMatch[1]) : null} </del> ); };
3. Codeタグのように行をまたいで成立し、かつタグの中で別の記法が成立するもの
Markdownでは画像のような行をまたいだ記法が存在します。



これに対応するため、改行コードを UTF-8 の \x00 に変換して、テキストすべてを1行の文字列に整えてから正規表現の走査を行います。 ※ \x00を利用するのは、ユーザーのキーボード入力では入力ができないためです ※ 一般的に利用される文字コードではバグの原因となります
下記の正規表現は1行に変換された文字列から Blockquote の記法を検知するためのものです。 これを1行となったテキストに実行することで、 Blockquote の Component に置き換えます。
'> Blockquoteだよ> 二行目> > 段落1> > 段落2'.match(new RegExp(`((^|\\x00)(\\> )+(.*?)(\\x00|$)){1,}`));
しかしこのままでは Blockquote は一行の文字列になってしまうため、先ほど変換した \x00 を使って改行を行います。 Blockquote の場合は、 \x00 ごとに div タグでくくる処理を加えます。 そしてCodeタグの中でさらに別の記法が成立するため、2. と同様に二重で走査を行います。
4. 改行
マークダウンは複数改行を行なっても、一行に変換されるものが一般的ですが、 TUNAG では複数改行をそのまま有効にするように作られています。 これは単に走査された \x00 をコンポーネントに置き換えるだけの処理になります。
const Line = () => { return ( <span className="markdown__line" /> ); };
5. 1〜4のどれにも属さない文字列
1〜4 のどれにも属さない文字列はそのまま span タグでくくっただけのコンポーネントに置き換えます。
const String = ({ decoratedText }) => { return ( <span className="markdown__str"> {decoratedText} </span> ); };
Markdownだけじゃ足りない、更なる要望
マークダウンの実装だけではなく、下記のような要望を社内やユーザーさんから頂いたため、機能の拡張を行いました。
- 「...もっと見る」によるフィードの省略
- 「ナイスプレーしたメンバー」など、マークダウンでないパーツの埋め込み
- 複数改行をしたい
まだこれだけでなく、たくさんの要望が積もっているため、随時対応していきたいと思います。

最後に
いかがだったでしょうか。本当にざっくりでしたが、Markdownの仕組みを解説しました。 しかし実際にはこの説明ほど単純ではなく、更に地獄が待ち受けているのが現実です。 👻もし挑まれるなら心して掛かるように...💀