こんにちは。エンジニアの河井です。 7月11に日に開催された Google Developers ML summit Tokyo の参加報告記事です。
参加の背景
サービスの規模が拡大してきたこと、データ集計基盤を構築したこと、ダッシュボードを整備したことなどから、次は分析を自動化できると良いのではないかと個人的に考えていて、情報収集のために参加しました。
Jeff Deam 氏によるキーノートセッション
Google の AI 研究チーム Google Brain のトップを務める Jeff Dean 氏のセッションです。
機械学習を必要とする問題に対して専門家が少なすぎるという問題意識から、現在の
solution = ML expert + data + computationという関係性を、将来的には
solution = data + computationにしたいという強いモチベーションをもっていることが伝わってきました。

そのような文脈から研究が進んでいる AutoML は、データに適合する機械学習モデルを自動で探索します。 画像・自然言語・テーブルデータなど、様々な形式のデータに対して成果が出てきているようです。
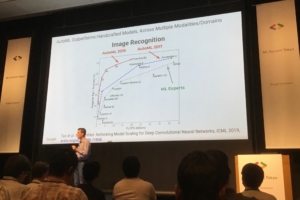 画像認識において、AutoML の自動探索によるモデルが専門家が構築したものより高精度を出したというものです。上のスライドはこちらの論文に載っています。
画像認識において、AutoML の自動探索によるモデルが専門家が構築したものより高精度を出したというものです。上のスライドはこちらの論文に載っています。
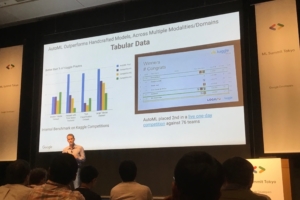 こちらは機械学習モデルの精度を競うコンペティションで、テーブルデータ課題において AutoML チームが2位に入賞した話です。報告記事はこちらです。
こちらは機械学習モデルの精度を競うコンペティションで、テーブルデータ課題において AutoML チームが2位に入賞した話です。報告記事はこちらです。
他にも機械学習全般の話や、AI開発におけるガイドなどありましたが、総じて AutoML を強く推している印象を受けました。 機械学習の各分野で次々と成果を出している Google が、この世界観をどのレベルで実現するのかを考えるとワクワクしますね。
Auto ML について
続いてクラウドサービスとしての AutoML 関連のセッションに参加しました。 精度の高いモデルを作るという点が強調されがちだが、プロダクションへの配信からその後の運用までを幅広くカバーするものだということを説明していました。

学習時に優先する要素の設定やモデルのバージョン管理機能なども含め、機械学習のワークフローにおいて属人性を排することに繋がりそうなので、プロダクション環境で機械学習システムを運用する際には選択肢として入ってきそうだなという印象を受けました。
AutoML Vision 活用事例
Twitter で話題になったラーメン二郎分類器の開発者である土井さんの発表で、もともと自前で実装・チューニングしたモデルと AutoML Vision で学習したモデルを比較してみたという話です。
土井さんが自前で学習したモデルは、最新の手法を論文から取り入れつつモデル構築やデータ拡張・パラメータチューニングをしたもので、分類精度は 99% を超えるということで、非常に精度が良いモデルが出来上がっています。 対する AutoML の成果ですが、限界まで学習させた結果、なんと 98% の精度を達成しました。 本当にデータセットとアノテーションだけで、専門家がチューニングしたモデルに匹敵するものが出来上がるとは、と感動しました。しかしながら今はまだ完璧ではなく、学習時間が長い、モデルサイズが大きくて推論時間が遅い、それでいて精度はまだ負けています。
PoC的なものはこれでサクッと立ち上げて、プロダクションに乗せるとなったら専門家がチューニングしたものを使うのが良さそうです。
まとめ
機械学習研究の最先端を行く企業の中の人達の話を直接聞ける機会はとても貴重で、多くの学びがありました。 専門家がいなくても機械学習を、というメッセージを色々な場面よく見かけるようになりました。誰でも精度の高いモデルを作れるということだけがその真意ではなく、学習から配信・運用までをクラウドサービスのエコシステムでまとめて取り扱えるようにする、という意味合いも兼ねています。 精度面ではまだまだ専門家に劣るところはあるものの、機械学習技術の研究は日々めまぐるしく進歩しているので、今後に期待しつつキャッチアップを怠らないようにしたいですね。